Do you know how your test cases are processed when you hit the Run button? Let’s
dive in to understand the architecture behind the deploy engine that underpins
the ZeuZ platform.
Challenges
Roughly 1.5+ year ago, ZeuZ server would simply hang (100% cpu usage) or crash
when you deployed 500+ test cases at a time. It would remain unavailable for
more than 5 minutes at stretch making it unusable for practical scenarios. Our
clients generally have 2-4k+ test cases and deploy about 500+ test cases every
day via manual deploy, CI/CD or automated schedulers. This made it impossible to
scale out.
To solve this challenge, I set out to write a completely new deploy engine using
Go replacing the older one written in Python. The result? We can now deploy
thousands of test cases without the cpu usage going over 5-10%. I’ll talk about
the intricacies and implementation details of the new engine in a separate post,
this post is more of an overview of the current architecture.
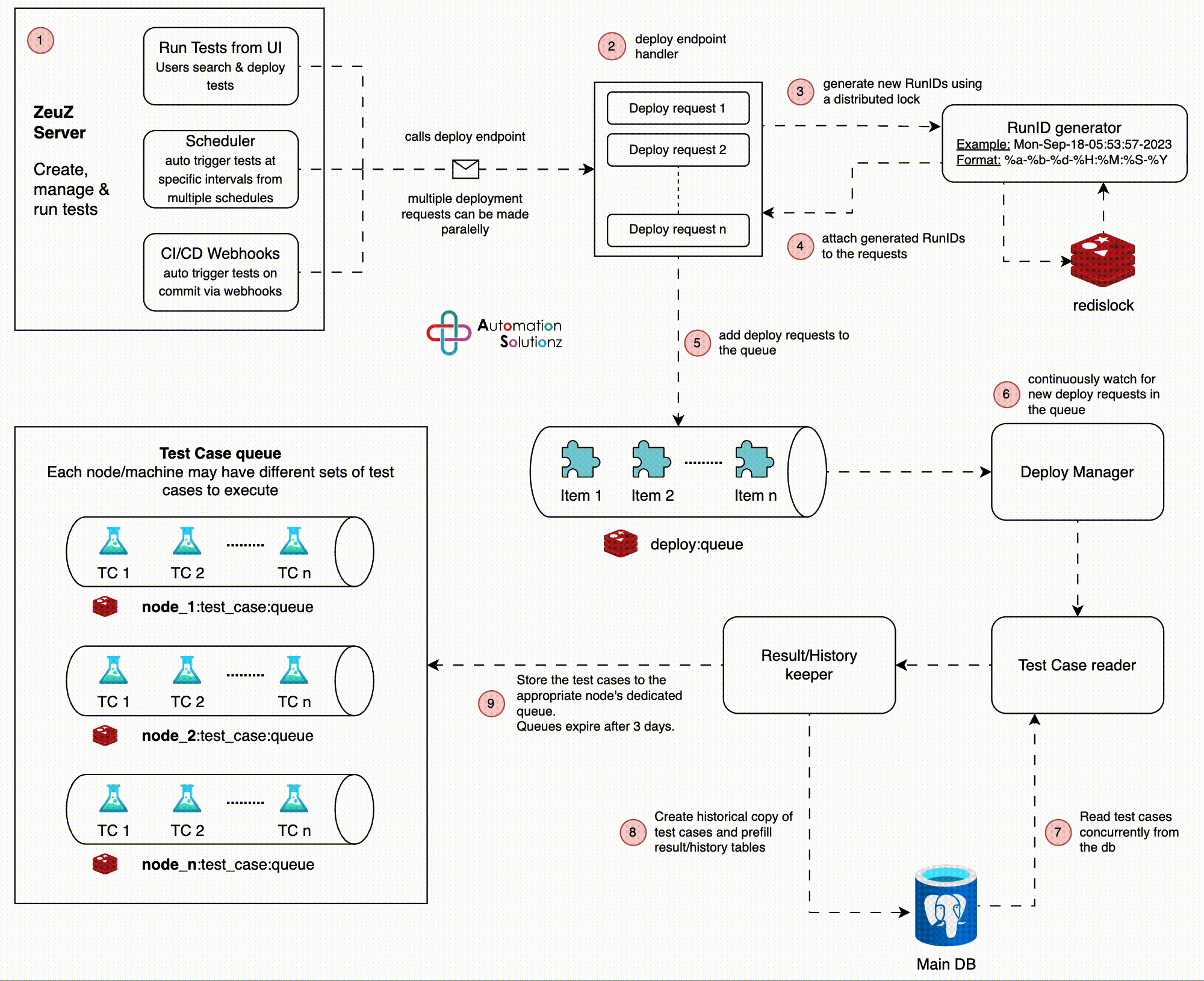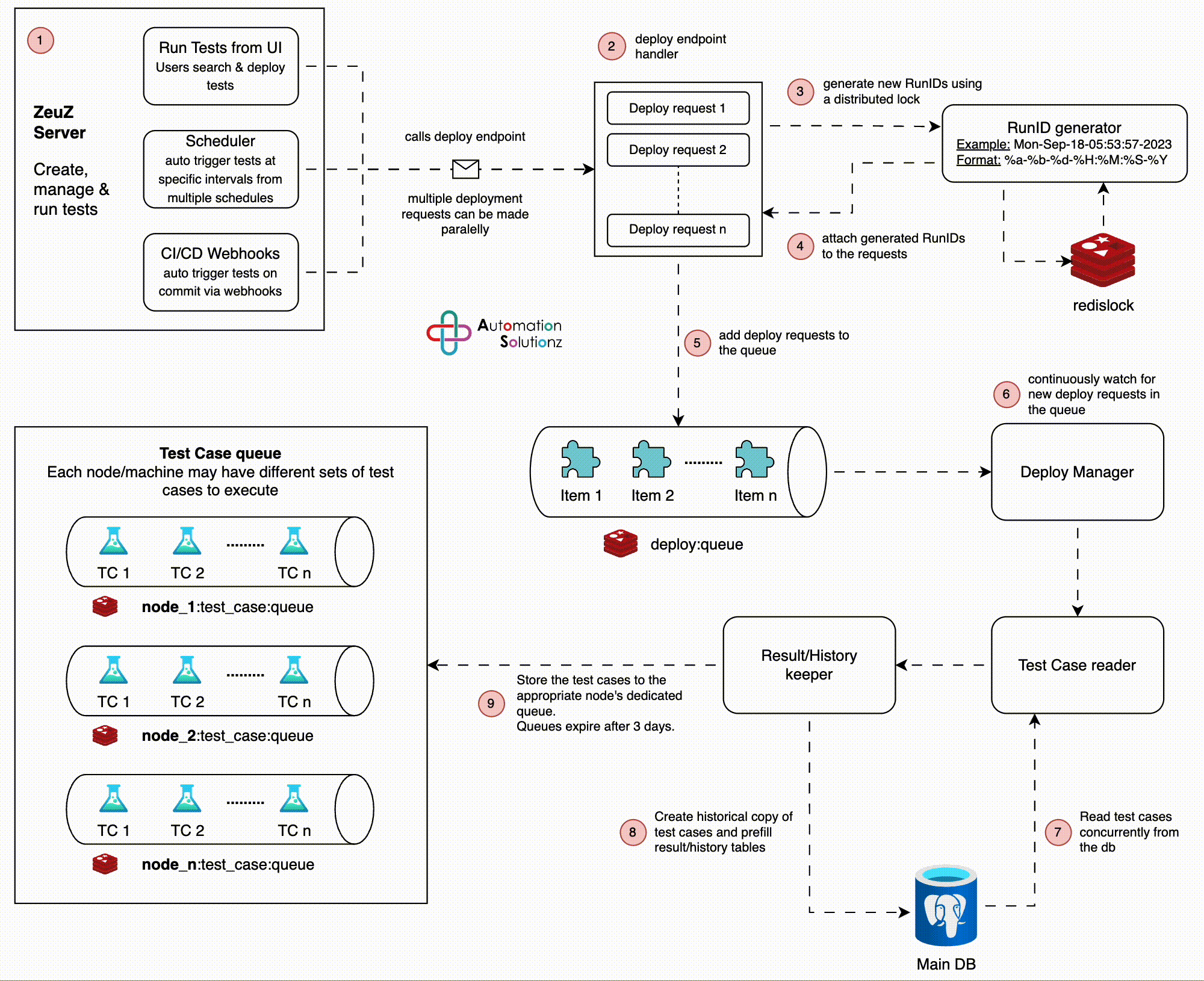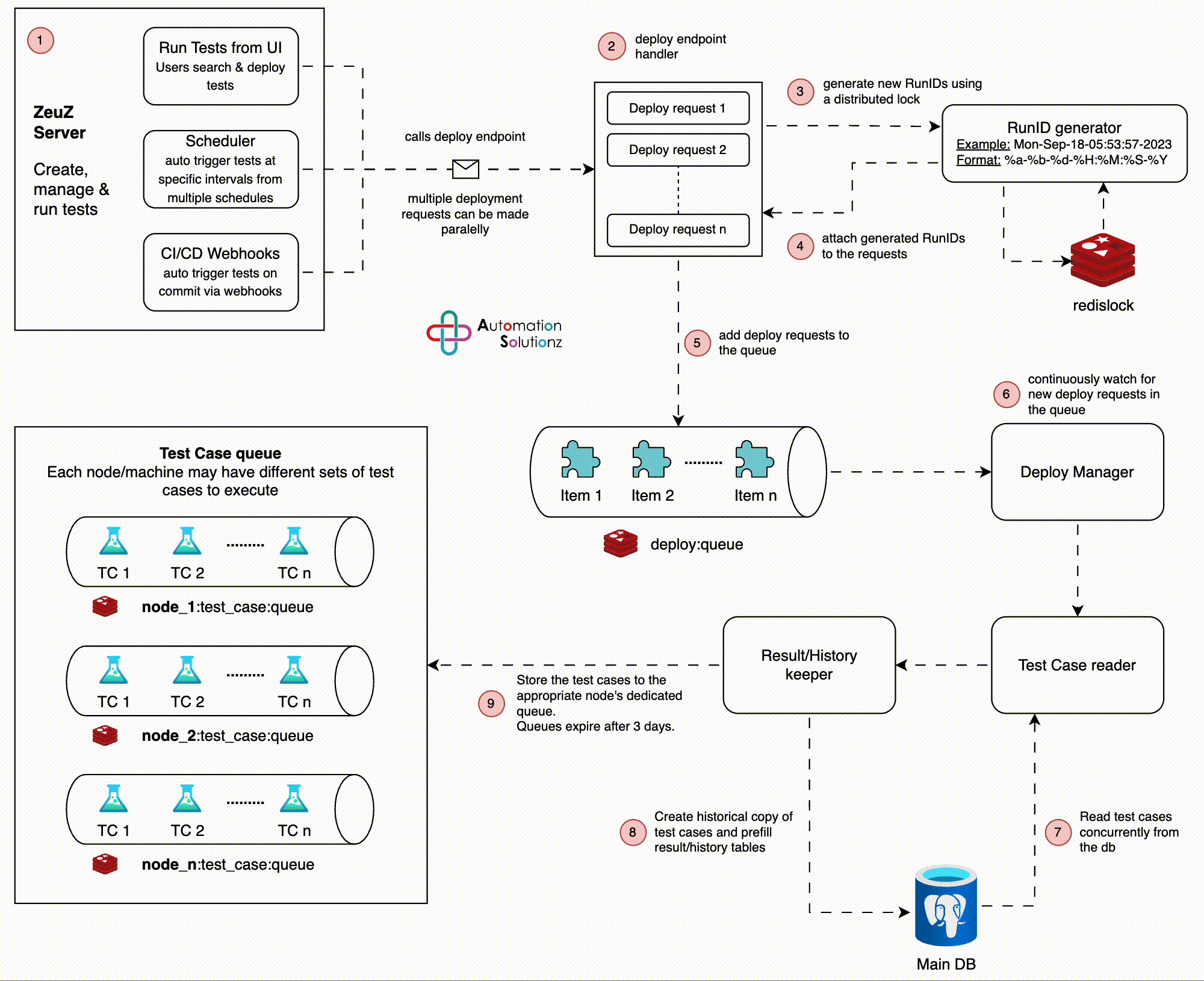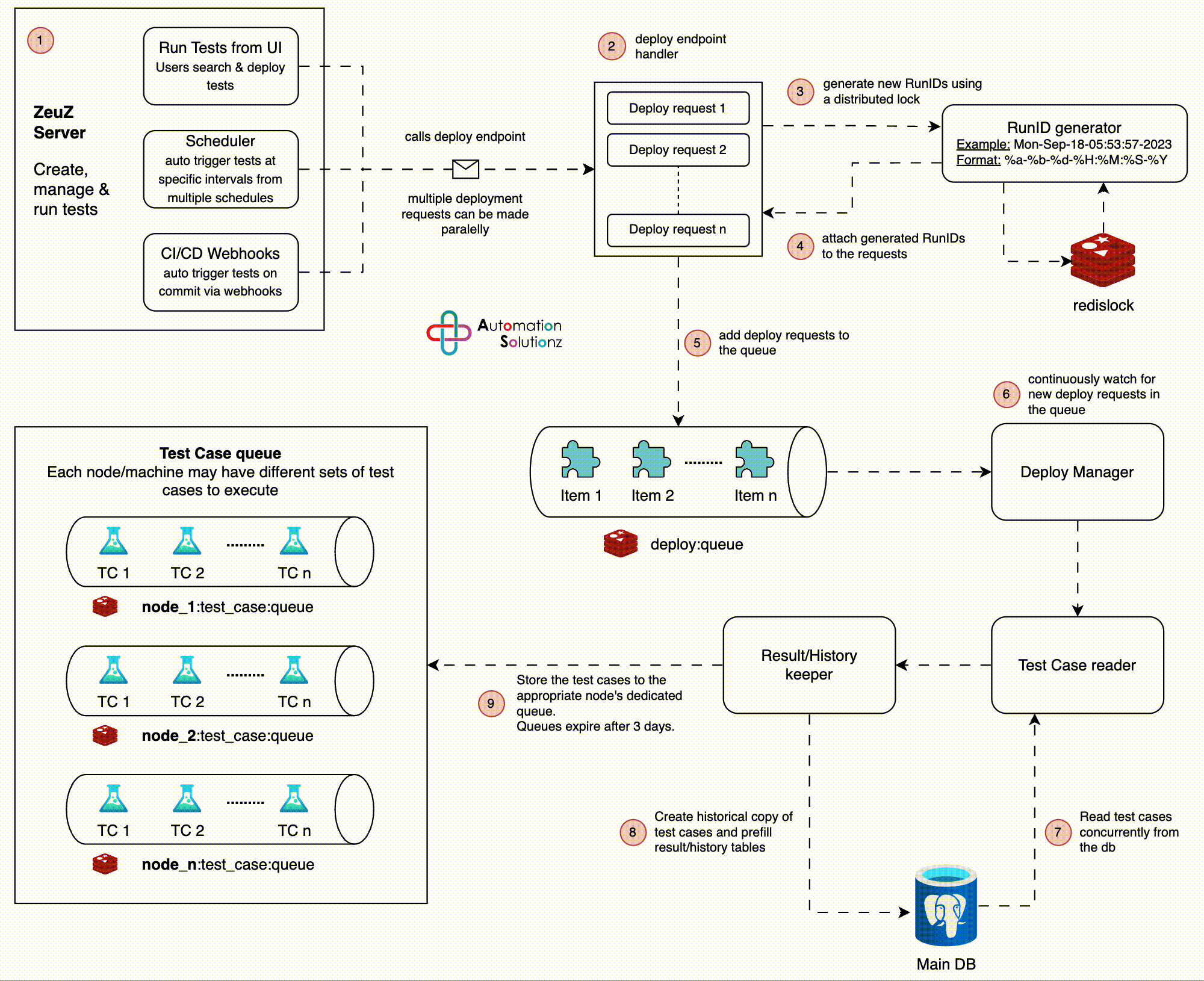
Architecture
Users, Scheduler or CI/CD triggers a new test set deployment.
The deploy endpoint handler takes the request and generates a new RunID. Note
that, multiple parallel calls to the deploy endpoint is fairly normal.
A RunID is a timestamp based format where the smallest unit to differentiate
between two RunIDs is a single “second”. This means, we cannot have two
RunIDs generated on the same second! To avoid generating two exact same
RunIDs, we use a distributed-mutex lock based on Redis to pause for 1 sec
every time a new RunID is generated.
Attach the generated RunIDs to the deploy requests.
Serialize the deploy requests and put them in a Redis queue (a sorted set to
be precise).
Deploy Manager - an embedded service that runs an infinite loop to
continuously watch for new deploy requests in the queue. As soon as a new
deploy request is found, it is passed on to a background worker.
The background worker reads the test cases listed in the deploy request from
the main database and passes the data to the Result Keeper.
The Result Keeper takes the test cases as they’re passed in and create
historical records in the database. To optimize the database operations, we
perform table-to-table copy for a portion of the data.
The test cases are then stored in separate queues identified by the “node id”
of deploy requests.
This concludes the architecture of the deployment process. After a ZeuZ node
connects to the server, it’ll request to see if test cases are available in the
queue identified by its “node id” - I’ll discuss this in a separate post.
Concepts
ZeuZ Server - a test case (+project management) platform to author, manage and
run both automated and manual tests.
ZeuZ Node - automation engine (agent) that runs on your desktop, cloud VM, etc
takes instructions from the server, executes them (open app/browser, go to
link, click on buttons, etc) and sends the report of the execution back to the
server.
RunID - each deploy request is assigned a unique timestamp based ID to
differentiate from other deploy requests. Example: Mon-Sep-18-09:54:53-2023.
We have plans to fix the limitation later, but with the scale we deal with,
this is more than enough.